
1. 개요
홍정모 교수님의 자료구조 강의 중 이진 탐색 트리 쪽을 공부했다. 강의 마지막에 미니 프로젝트로 영어 사전 만드는 것을 추천했다. 그래서 공부한 이진 탐색 트리를 활용하는 연습을 해볼겸 간단한 영어 사전 프로그램을 만들기로 했다. 영어 사전 프로그램은 단어와 뜻 정보가 있는 텍스트 파일을 읽어 들인다. 그리고 그 데이터를 이진 탐색 트리 형태로 저장한다. 프로그램에 사용자가 단어를 입력하면 트리에서 단어를 탐색 후 뜻을 출력한다.

2. 구조
2.1. String
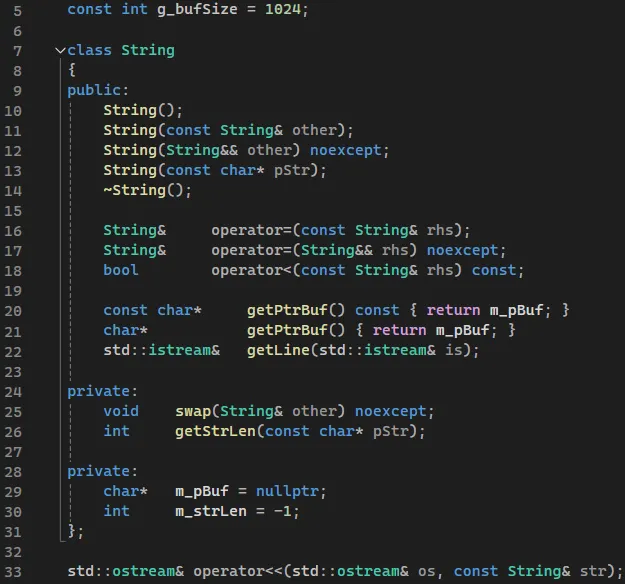
문자열을 다루기 위한 클래스이다. C++에서 문자열을 다룰 땐 보통 std::string 클래스를 활용한다. 하지만 굳이 따로 문자열 클래스를 만든 이유는 문자열 관련 구현 연습을 해보고 싶어서 만들어봤다. m_pBuf 멤버 변수가 문자열이 저장된 배열을 가리키는 포인터다. 생성 시 문자열을 위한 메모리를 동적 할당하는데 g_bufSize 전역 변수의 크기만큼 할당한다. 동적 리소스에 대한 포인터를 소유하고 있으므로 복사, 이동 관련 생성자와 대입 연산자를 구현했다. 복사 시 깊은 복사를 하고 이동 시 이전 객체와 모든 멤버를 스왑한다. 이진 탐색 트리에서 단어 비교가 필요하기 때문에 비교 연산자를 구현했다. getLine 메서드는 입력 스트림으로부터 한 줄 입력받는다. 파일에서 입력받는 것을 편하게 하기 위해 추가했다.
2.2. BinarySearchTree
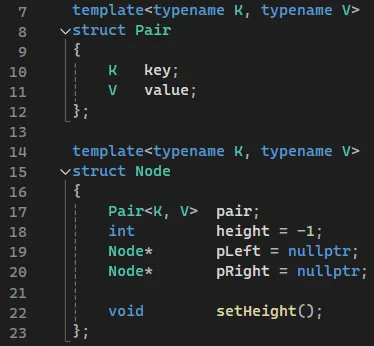

이진 탐색 트리를 구현한 클래스 템플릿이다. 트리의 노드는 Node 구조체로 정의했고 키와 값은 Pair 구조체 형태로 저장한다. insert와 remove 메서드는 재귀적으로 삽입, 삭제를 수행한다. balance, rotateLeft, rotateRight메서드는 AVL 트리 형태로 균형을 맞추기 위해 존재한다. 트리의 탐색, 삽입, 삭제 연산의 시간 복잡도는 트리 높이에 의해 결정되므로 성능을 위해선 균형을 맞춰 높이를 최소화해야 한다.
2.2. EnglishDictionary
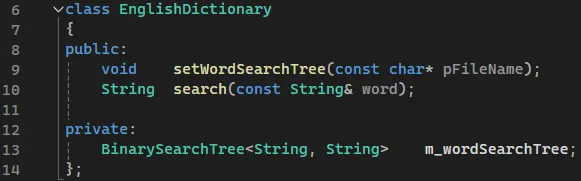
영어 사전을 구현한 클래스다. 멤버는 단어 탐색 트리인데, 단어를 key, 단어의 뜻을 value로 저장한다. setWordSearchTree메서드의 파라미터에 단어와 의미 정보가 있는 파일의 이름을 넘기면 파일을 읽고 단어 탐색 트리에 저장한다. 단어, 의미 정보 파일은 단어 한 줄과 의미 한 줄의 두 줄 단위 데이터로 기록된 텍스트 파일이다. search메서드는 단어를 인자로 넘기면 트리에서 탐색 후 뜻을 반환한다.
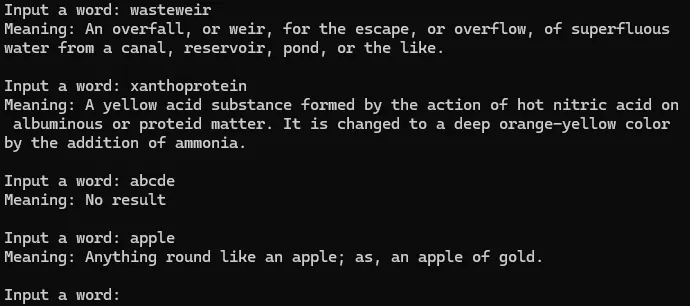
3. 동작

main 함수의 프로그램 로직이다. 처음에 텍스트 파일 이름을 인자로 넘겨서 EnglishDictionary 객체를 만든다. 객체 생성 후에는 사용자에게 단어를 입력받고 의미를 탐색해서 출력하는 과정을 반복한다.
4. 성능
홍정모 교수님 강의에서 제공해준 텍스트 파일 데이터는 169,888 줄의 양이다. 이 텍스트 파일을 사용하면 프로그램을 실행했을 때 트리가 완성되기까지 14~15초 정도가 소요되고 단어를 검색할 땐 7~12ms 정도가 걸린다. 메모리는 133MB를 사용한다. 프로젝트를 진행하면서 해시 테이블 진도를 같이 나갔는데 영어 사전을 해시 테이블로 저장한다면 이진 탐색 트리 영어 사전과 성능 차이가 얼마나 날지 궁금하다. 해시 테이블의 경우 속도는 더 빠르지만 메모리는 더 많이 사용할 것 같다. 나중에 해시 테이블로 사전을 구현해 봐야겠다.